The most costly AI video mistake creators make isn't model selection, prompt engineering quality, or parameter configuration-it's generating expensive video directly from text prompts without image-stage validation catching compositional failures instantly visible in static form.
Direct text-to-video generation commits 8-15 minutes processing time and substantial credit allocation discovering issues (wrong composition, failed lighting, subject placement problems, stylistic mismatches) detectable in 10-20 seconds via rapid image generation. This workflow error compounds each time you create ai videos, wasting 40-60% of video processing budgets on preventable failures and creating frustration-driven abandonment patterns. When you do promote a validated frame to motion, run the expensive pass inside your text-to-video workflow only after the still reads clean. On OpenAI's line, Sora 2 Turbo is the usual place to burn cheap motion tests before you lock a finals-tier render.
This analysis examines why image-first validation workflows dramatically improve video success rates, documents efficiency economics favoring staged validation, and establishes practical implementation frameworks preventing the single most expensive workflow mistake systematically.
The Core Mistake: Direct Text-to-Video Generation
Common Pattern:
- Craft detailed text prompt attempting to anticipate all visual requirements
- Submit to video generation model (Veo, Sora, Kling: 8-15 minutes processing)
- Review output discovering fundamental compositional failures:
- Subject positioned incorrectly within frame
- Lighting atmosphere mismatched to creative intent
- Color palette deviating from brand requirements
- mastering camera motion in AI video inappropriate for subject showcase
- Background elements competing with focal subject
- Adjust prompt attempting to correct discovered issues
- Regenerate (another 8-15 minutes) often revealing new problems
- Repeat cycle 3-5 times before acceptable output or frustrated abandonment
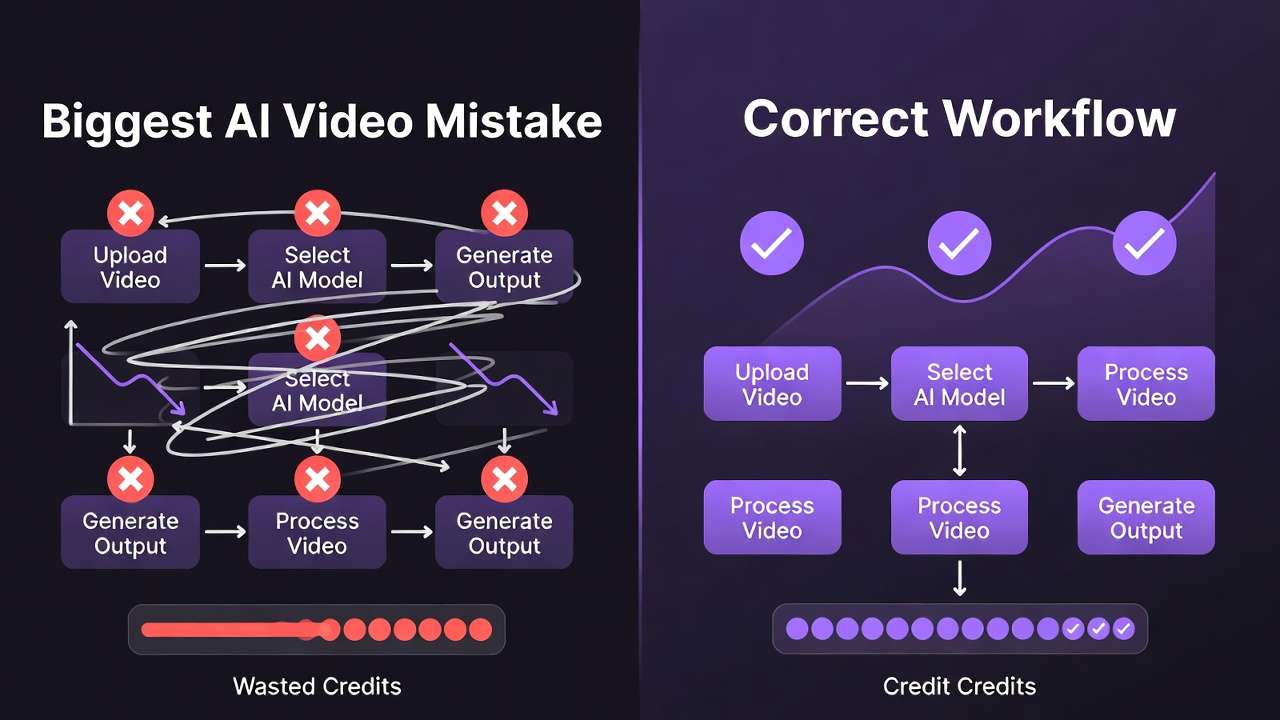
Timeline: 45-75 minutes for single validated video via trial-and-error iteration Budget Impact: 3-5 video generation credits consumed per successful output Success Rate: 20-35% first-attempt acceptability documented in creator workflow analyses
Root Problem: Text prompts interpreted differently by models lacking visual reference constraints. Compositional intent communicated ambiguously through language versus precisely via image examples.
Why Image-First Validation Solves This
Staged Workflow Architecture:
Stage 1: Rapid Image Concept Generation (2-5 minutes)
- Generate 8-12 image variations via Flux 2, Imagen 4, or Midjourney
- Test diverse compositional approaches, lighting styles, color palettes
- Instant visual feedback reveals successful versus failed directions immediately
- Stakeholder/client review provides clear selection without motion processing commitment
Stage 2: Image Refinement (3-8 minutes total)
- Generate seed-locked variations of strongest image candidates
- Test minor compositional adjustments via parameter tweaks
- Validate final composition meeting all creative requirements visually
- Document seeds and parameters of approved foundation
Stage 3: Video Generation With Image Reference (5-10 minutes)
- Animate approved image via appropriate VideoGen model (Veo, Sora, Kling)
- Image reference constrains motion generation maintaining validated aesthetic
- Prompt focuses exclusively on motion characteristics versus complete scene description
- Processing time allocated to validated composition rather than exploratory guesswork
Total Timeline: 15-25 minutes for validated video output
Budget Impact: 1-2 video generation credits per successful output
Success Rate: 65-85% first-attempt acceptability with image-guided approach
Efficiency Gain: 50-70% time savings, 60-75% credit savings, 2-3x higher success rates versus direct text-to-video generation patterns.
Economic Analysis: Image vs Video Processing
Image Generation Characteristics:
- Processing Time: 10-30 seconds per output (Flux 2, Imagen 4)
- Credit Cost: Minimal (1-2% of video generation equivalent)
- Iteration Velocity: 15-20 variations testable in 10 minutes
- Failure Cost: 10-20 seconds wasted per unsuccessful attempt
- Visual Clarity: Compositional issues instantly apparent in static form
Video Generation Characteristics:
- Processing Time: 8-15 minutes per output (Veo, Sora, Kling depending on duration/quality)
- Credit Cost: Substantial (10-20x image generation equivalent)
- Iteration Velocity: 3-4 variations testable in 45-60 minutes
- Failure Cost: 8-15 minutes wasted per unsuccessful attempt
- Visual Clarity: Compositional issues obscured by motion, requiring complete playback review
Strategic Implication: Compositional failures caught at image stage (20 seconds) versus video stage (10 minutes) transforms workflow economics dramatically. Testing 12 compositional approaches via images (6 minutes) versus video (120+ minutes) enables 20x exploration velocity.
Common Objections Addressed
Objection 1: "My prompts areprompt lengthugh"
Reality: Language ambiguity persists regardless of prompt length. "Dramatic lighting" interpreted differently by models; image examples provide precise visual constraints text cannot match. Documented workflows show experienced prompt engineers still achieve only 40-50% first-attempt success via text-only video generation.
Objection 2: "Image-to-video produces less dynamic results"
Reality: Modern VideoGen models (Veo 3.1, Sora 2, Kling 2.5) with image references produce motion quality equivalent to text-only generation while maintaining compositional control. Motion characteristics specified via prompt; composition controlled via reference image. Creator comparisons show no perceptible quality difference in blind tests.
Objection 3: "Adding image stage takes longer overall"
Reality: Measured timelines prove opposite-image validation eliminates expensive video regeneration cycles. 15-minute staged workflow consistently faster than 45-minute trial-and-error direct approach. Time investment shifted from reactive regeneration (uncertain timeline) to proactive validation (predictable staging).
Objection 4: "I don't know image generation tools"
Reality: Basic image generation proficiency achievable in 30-60 minutes via models like Flux 2 or Imagen 4. Investment pays off immediately through video workflow efficiency gains. Multi-model platforms provide unified access eliminating separate tool learning curves.
Practical Implementation Framework
Step 1: Establish Image Generation Baseline Proficiency
- Select primary image model (Flux 2 for photorealism, Midjourney for artistic, Imagen 4 for balanced)
- Test 20-30 prompts across diverse subjects learning output characteristics
- Document seed ranges performing well per subject category
- Build using negative prompts effectively library preventing common artifacts
- Timeline: 2-3 hours initial investment

Step 2: Develop Image-First Workflow Habit
- Default to image validation for any video project allowing 30+ minute timeline
- Generate 6-10 image concepts before video commitment
- Stakeholder review at image stage (synchronous or asynchronous)
- Seed documentation of approved foundations
- Timeline: Becomes 10-15 minute routine per project
Step 3: Optimize Image-to-Video Transition
- Learn reference passing mechanics per VideoGen model
- Develop motion-focused prompt templates (composition established via image)
- Test model-specific image-to-video characteristics (Veo physics, Sora narrative, Kling energy)
- Build model selection criteria based on motion requirements
- Timeline: 1-2 hours experimentation per primary VideoGen model
Step 4: Measure and Refine
- Track success rates (first-attempt acceptability percentage)
- Monitor regeneration requirements (iterations per final output)
- Calculate time-per-asset across workflow stages
- Refine image validation criteria based on video failure patterns
- Timeline: Ongoing optimization through documented observation
When Direct Video Generation Remains Appropriate
Exception Scenarios:
Proven Prompt-Seed Combinations: Creators with extensively tested text-only prompts and documented seeds achieving 70%+ success rates may skip image validation for routine production matching proven patterns.
Pure Motion Requirements: Projects where composition matters less than motion characteristics (abstract animation, motion graphics, certain effects-driven content) may benefit from direct video experimentation.
Extreme Time Constraints: Contexts demanding immediate single-output delivery without iteration opportunity (live presentations, real-time demonstrations) necessitate direct attempts despite efficiency costs.
Established Image Libraries: Projects building on existing image libraries with proven video animation success may proceed directly from archived references without new image generation.
Implementation Guideline: Default to image-first validation; reserve direct video generation for documented exception scenarios only.
ROI Calculation: Image-First Investment
Scenario: Agency producing 20 video assets weekly

Direct Text-to-Video Approach:
- 45 minutes average per asset (including regeneration cycles)
- 15 hours weekly team time
- 60-80 video generation credits consumed (including failed attempts)
Image-First Staged Approach:
- 20 minutes average per asset (image validation + guided video)
- 6.7 hours weekly team time
- 25-30 video generation credits consumed (minimal failures)
Measured Gains:
- 8.3 hours weekly time savings (55% efficiency improvement)
- 35-50 credits weekly budget savings (60% cost reduction)
- Higher output quality through validated foundations
- Reduced team frustration from failed regeneration cycles
Annual Impact (50 working weeks):
- 415 hours recovered (10+ working weeks annually)
- 1,750-2,500 credits saved
- Measurable client satisfaction improvement through consistent quality
Related Articles
- Text-to-Video vs Image-to-Video
- Chaining Image Video Upscaling
- AI Video Ads for Facebook & Instagram: Complete Performance Guide
- AI workflow failure points
Understanding why image-first validation prevents the costliest workflow mistake transforms production economics. Master Understanding AI Video Generation Pipelines: Complete Guide building efficient workflows that validate before committing expensive processing resources systematically.